Lab Activity 201: Exploring Hyperparameters (Activation Functions and Optimizers)#
Objective#
In this lab, we explore how different activation functions and optimizers affect the performance of a deep learning model. We apply these hyperparameters to the Fashion-MNIST dataset and analyze how each configuration influences model training and accuracy.
Dataset Overview#
# Import libraries and setup device
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transforms
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
import time
# Device configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 9
7 import matplotlib.pyplot as plt
8 import numpy as np
----> 9 from tqdm import tqdm
10 import time
12 # Device configuration
ModuleNotFoundError: No module named 'tqdm'
Technical Setup#
This section imports all necessary libraries and configures the computing device. We use:
PyTorch for deep learning framework
Matplotlib for visualization
NumPy for numerical operations
tqdm for progress bars
The device is automatically configured to use GPU if available, otherwise CPU.
# Load Dataset and Create DataLoaders
# Define image transformations
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# Download Fashion-MNIST training and testing datasets
train_data = datasets.FashionMNIST(root='data', train=True, download=True, transform=transform)
test_data = datasets.FashionMNIST(root='data', train=False, download=True, transform=transform)
# Create DataLoaders
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False)
# Dataset info
print(f"Training samples: {len(train_data)}")
print(f"Test samples: {len(test_data)}")
print(f"Number of classes: {len(train_data.classes)}")
print(f"Classes: {train_data.classes}")
100%|██████████| 26.4M/26.4M [00:16<00:00, 1.64MB/s]
100%|██████████| 29.5k/29.5k [00:00<00:00, 91.3kB/s]
100%|██████████| 4.42M/4.42M [00:05<00:00, 765kB/s]
100%|██████████| 5.15k/5.15k [00:00<00:00, 5.15MB/s]
Training samples: 60000
Test samples: 10000
Number of classes: 10
Classes: ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Dataset Information#
Fashion-MNIST Dataset Characteristics:
Total Samples: 70,000 grayscale images
Training Set: 60,000 images
Test Set: 10,000 images
Image Size: 28×28 pixels
Number of Classes: 10
Class Labels: 0. T-shirt/top, 1. Trouser, 2. Pullover, 3. Dress, 4. Coat, 5. Sandal, 6. Shirt, 7. Sneaker, 8. Bag, 9. Ankle boot
Preprocessing:
Images normalized to range [-1, 1]
Batch size: 64 for efficient training
Training data shuffled for better generalization
# Define Flexible CNN Model
class FlexibleCNN(nn.Module):
def __init__(self, activation_func='relu'):
super(FlexibleCNN, self).__init__()
self.activation_func = activation_func
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def get_activation(self, x):
if self.activation_func == 'relu':
return F.relu(x)
elif self.activation_func == 'leaky_relu':
return F.leaky_relu(x, 0.1)
elif self.activation_func == 'elu':
return F.elu(x)
elif self.activation_func == 'sigmoid':
return torch.sigmoid(x)
elif self.activation_func == 'tanh':
return torch.tanh(x)
else:
return F.relu(x) # default
def forward(self, x):
x = self.get_activation(self.conv1(x))
x = self.get_activation(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.get_activation(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
Model Architecture#
CNN Structure:
Convolutional Layers: 2 layers (32 and 64 filters)
Activation Functions: Configurable (ReLU, LeakyReLU, ELU, Sigmoid, Tanh)
Pooling: Max pooling with 2×2 window
Dropout: Two dropout layers (25% and 50%) for regularization
Fully Connected: Two linear layers (9216→128→10)
Output: LogSoftmax for multi-class classification
Key Features:
Flexible activation function selection
Dropout for preventing overfitting
Consistent architecture across all experiments
# Define Training and Evaluation Functions
def train_model(model, train_loader, optimizer, criterion, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = 100 * correct / total
return train_loss, train_acc
def evaluate_model(model, test_loader, criterion, device):
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_loss = test_loss / len(test_loader)
test_acc = 100 * correct / total
return test_loss, test_acc
def run_experiment(activation_func, optimizer_name, learning_rate=0.001, num_epochs=10):
print(f"\n=== Experiment: {activation_func.upper()} + {optimizer_name.upper()} ===")
# Initialize model
model = FlexibleCNN(activation_func=activation_func).to(device)
criterion = nn.NLLLoss() # Since we're using LogSoftmax
# Initialize optimizer
if optimizer_name == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
elif optimizer_name == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
elif optimizer_name == 'rmsprop':
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)
elif optimizer_name == 'adagrad':
optimizer = torch.optim.Adagrad(model.parameters(), lr=learning_rate)
else:
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Track metrics
train_losses = []
train_accs = []
test_losses = []
test_accs = []
# Training loop
for epoch in range(num_epochs):
train_loss, train_acc = train_model(model, train_loader, optimizer, criterion, device)
test_loss, test_acc = evaluate_model(model, test_loader, criterion, device)
train_losses.append(train_loss)
train_accs.append(train_acc)
test_losses.append(test_loss)
test_accs.append(test_acc)
print(f'Epoch [{epoch+1}/{num_epochs}] - '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}% | '
f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')
return {
'model': model,
'train_losses': train_losses,
'train_accs': train_accs,
'test_losses': test_losses,
'test_accs': test_accs,
'final_train_acc': train_accs[-1],
'final_test_acc': test_accs[-1]
}
Training Configuration#
Training Parameters:
Epochs: 15 for each experiment
Batch Size: 64
Learning Rate: 0.001 (consistent across experiments)
Loss Function: Negative Log Likelihood Loss (compatible with LogSoftmax)
Evaluation Metrics:
Training/Test Loss
Training/Test Accuracy
Convergence speed
Final performance metrics
Consistency Measures:
Same random seed for reproducibility
Identical training/validation splits
Fixed hyperparameters except activation functions and optimizers
# Define Experiment Configuration and Run Experiments
# Experiment configurations
experiments = [
{'activation': 'relu', 'optimizer': 'sgd', 'name': 'ReLU + SGD (Baseline)'},
{'activation': 'relu', 'optimizer': 'adam', 'name': 'ReLU + Adam'},
{'activation': 'leaky_relu', 'optimizer': 'sgd', 'name': 'LeakyReLU + SGD'},
{'activation': 'leaky_relu', 'optimizer': 'adam', 'name': 'LeakyReLU + Adam'},
{'activation': 'elu', 'optimizer': 'rmsprop', 'name': 'ELU + RMSprop'},
{'activation': 'sigmoid', 'optimizer': 'adam', 'name': 'Sigmoid + Adam'}
]
# Run all experiments
results = {}
num_epochs = 15
print("Starting Experiments...")
print("=" * 60)
for exp in experiments:
key = f"{exp['activation']}_{exp['optimizer']}"
results[key] = run_experiment(
activation_func=exp['activation'],
optimizer_name=exp['optimizer'],
num_epochs=num_epochs
)
results[key]['name'] = exp['name']
print("\nAll experiments completed!")
Starting Experiments...
============================================================
=== Experiment: RELU + SGD ===
Epoch [1/15] - Train Loss: 1.8201, Train Acc: 41.51% | Test Loss: 1.0716, Test Acc: 69.54%
Epoch [2/15] - Train Loss: 0.9596, Train Acc: 66.23% | Test Loss: 0.7306, Test Acc: 73.36%
Epoch [3/15] - Train Loss: 0.7788, Train Acc: 72.17% | Test Loss: 0.6546, Test Acc: 76.01%
Epoch [4/15] - Train Loss: 0.7145, Train Acc: 73.99% | Test Loss: 0.6168, Test Acc: 76.72%
Epoch [5/15] - Train Loss: 0.6722, Train Acc: 75.58% | Test Loss: 0.5883, Test Acc: 77.76%
Epoch [6/15] - Train Loss: 0.6414, Train Acc: 76.54% | Test Loss: 0.5647, Test Acc: 78.43%
Epoch [7/15] - Train Loss: 0.6184, Train Acc: 77.32% | Test Loss: 0.5467, Test Acc: 79.52%
Epoch [8/15] - Train Loss: 0.6000, Train Acc: 78.12% | Test Loss: 0.5313, Test Acc: 80.33%
Epoch [9/15] - Train Loss: 0.5856, Train Acc: 78.76% | Test Loss: 0.5192, Test Acc: 80.65%
Epoch [10/15] - Train Loss: 0.5716, Train Acc: 79.19% | Test Loss: 0.5133, Test Acc: 80.85%
Epoch [11/15] - Train Loss: 0.5589, Train Acc: 79.59% | Test Loss: 0.5008, Test Acc: 81.34%
Epoch [12/15] - Train Loss: 0.5487, Train Acc: 79.96% | Test Loss: 0.4927, Test Acc: 81.74%
Epoch [13/15] - Train Loss: 0.5397, Train Acc: 80.39% | Test Loss: 0.4831, Test Acc: 82.19%
Epoch [14/15] - Train Loss: 0.5292, Train Acc: 80.74% | Test Loss: 0.4729, Test Acc: 82.86%
Epoch [15/15] - Train Loss: 0.5226, Train Acc: 81.12% | Test Loss: 0.4716, Test Acc: 82.49%
=== Experiment: RELU + ADAM ===
Epoch [1/15] - Train Loss: 0.4828, Train Acc: 82.87% | Test Loss: 0.3022, Test Acc: 88.89%
Epoch [2/15] - Train Loss: 0.3206, Train Acc: 88.54% | Test Loss: 0.2802, Test Acc: 89.52%
Epoch [3/15] - Train Loss: 0.2716, Train Acc: 90.24% | Test Loss: 0.2389, Test Acc: 91.30%
Epoch [4/15] - Train Loss: 0.2415, Train Acc: 91.15% | Test Loss: 0.2530, Test Acc: 90.86%
Epoch [5/15] - Train Loss: 0.2212, Train Acc: 91.88% | Test Loss: 0.2283, Test Acc: 91.34%
Epoch [6/15] - Train Loss: 0.2048, Train Acc: 92.35% | Test Loss: 0.2232, Test Acc: 91.81%
Epoch [7/15] - Train Loss: 0.1891, Train Acc: 93.00% | Test Loss: 0.2181, Test Acc: 92.19%
Epoch [8/15] - Train Loss: 0.1762, Train Acc: 93.48% | Test Loss: 0.2293, Test Acc: 91.96%
Epoch [9/15] - Train Loss: 0.1647, Train Acc: 93.86% | Test Loss: 0.2281, Test Acc: 92.41%
Epoch [10/15] - Train Loss: 0.1505, Train Acc: 94.24% | Test Loss: 0.2229, Test Acc: 92.45%
Epoch [11/15] - Train Loss: 0.1445, Train Acc: 94.53% | Test Loss: 0.2253, Test Acc: 92.82%
Epoch [12/15] - Train Loss: 0.1379, Train Acc: 94.89% | Test Loss: 0.2313, Test Acc: 92.40%
Epoch [13/15] - Train Loss: 0.1334, Train Acc: 94.92% | Test Loss: 0.2442, Test Acc: 92.58%
Epoch [14/15] - Train Loss: 0.1232, Train Acc: 95.21% | Test Loss: 0.2285, Test Acc: 92.77%
Epoch [15/15] - Train Loss: 0.1196, Train Acc: 95.54% | Test Loss: 0.2476, Test Acc: 92.97%
=== Experiment: LEAKY_RELU + SGD ===
Epoch [1/15] - Train Loss: 1.9792, Train Acc: 38.96% | Test Loss: 1.2854, Test Acc: 67.28%
Epoch [2/15] - Train Loss: 1.0279, Train Acc: 65.15% | Test Loss: 0.7575, Test Acc: 73.38%
Epoch [3/15] - Train Loss: 0.7780, Train Acc: 72.41% | Test Loss: 0.6595, Test Acc: 75.78%
Epoch [4/15] - Train Loss: 0.7014, Train Acc: 74.59% | Test Loss: 0.6179, Test Acc: 77.25%
Epoch [5/15] - Train Loss: 0.6556, Train Acc: 76.20% | Test Loss: 0.5880, Test Acc: 78.02%
Epoch [6/15] - Train Loss: 0.6287, Train Acc: 77.27% | Test Loss: 0.5667, Test Acc: 78.79%
Epoch [7/15] - Train Loss: 0.6078, Train Acc: 77.89% | Test Loss: 0.5485, Test Acc: 79.72%
Epoch [8/15] - Train Loss: 0.5890, Train Acc: 78.64% | Test Loss: 0.5364, Test Acc: 80.11%
Epoch [9/15] - Train Loss: 0.5737, Train Acc: 79.12% | Test Loss: 0.5246, Test Acc: 80.52%
Epoch [10/15] - Train Loss: 0.5596, Train Acc: 79.72% | Test Loss: 0.5155, Test Acc: 80.95%
Epoch [11/15] - Train Loss: 0.5498, Train Acc: 80.20% | Test Loss: 0.5009, Test Acc: 81.58%
Epoch [12/15] - Train Loss: 0.5396, Train Acc: 80.44% | Test Loss: 0.4944, Test Acc: 81.83%
Epoch [13/15] - Train Loss: 0.5310, Train Acc: 80.66% | Test Loss: 0.4865, Test Acc: 82.31%
Epoch [14/15] - Train Loss: 0.5208, Train Acc: 81.12% | Test Loss: 0.4825, Test Acc: 82.19%
Epoch [15/15] - Train Loss: 0.5164, Train Acc: 81.31% | Test Loss: 0.4726, Test Acc: 82.76%
=== Experiment: LEAKY_RELU + ADAM ===
Epoch [1/15] - Train Loss: 0.4493, Train Acc: 83.82% | Test Loss: 0.3003, Test Acc: 89.36%
Epoch [2/15] - Train Loss: 0.2935, Train Acc: 89.27% | Test Loss: 0.2630, Test Acc: 89.97%
Epoch [3/15] - Train Loss: 0.2497, Train Acc: 90.81% | Test Loss: 0.2393, Test Acc: 91.21%
Epoch [4/15] - Train Loss: 0.2210, Train Acc: 91.94% | Test Loss: 0.2484, Test Acc: 90.67%
Epoch [5/15] - Train Loss: 0.1999, Train Acc: 92.63% | Test Loss: 0.2342, Test Acc: 91.96%
Epoch [6/15] - Train Loss: 0.1840, Train Acc: 93.16% | Test Loss: 0.2359, Test Acc: 92.12%
Epoch [7/15] - Train Loss: 0.1689, Train Acc: 93.73% | Test Loss: 0.2246, Test Acc: 92.17%
Epoch [8/15] - Train Loss: 0.1578, Train Acc: 94.06% | Test Loss: 0.2240, Test Acc: 92.06%
Epoch [9/15] - Train Loss: 0.1487, Train Acc: 94.42% | Test Loss: 0.2286, Test Acc: 92.12%
Epoch [10/15] - Train Loss: 0.1372, Train Acc: 94.94% | Test Loss: 0.2296, Test Acc: 92.41%
Epoch [11/15] - Train Loss: 0.1305, Train Acc: 95.08% | Test Loss: 0.2340, Test Acc: 92.49%
Epoch [12/15] - Train Loss: 0.1220, Train Acc: 95.47% | Test Loss: 0.2358, Test Acc: 92.30%
Epoch [13/15] - Train Loss: 0.1182, Train Acc: 95.53% | Test Loss: 0.2345, Test Acc: 92.78%
Epoch [14/15] - Train Loss: 0.1108, Train Acc: 95.82% | Test Loss: 0.2447, Test Acc: 92.57%
Epoch [15/15] - Train Loss: 0.1056, Train Acc: 96.10% | Test Loss: 0.2578, Test Acc: 92.35%
=== Experiment: ELU + RMSPROP ===
Epoch [1/15] - Train Loss: 0.5388, Train Acc: 82.47% | Test Loss: 0.3824, Test Acc: 85.70%
Epoch [2/15] - Train Loss: 0.3369, Train Acc: 87.99% | Test Loss: 0.3493, Test Acc: 86.77%
Epoch [3/15] - Train Loss: 0.2964, Train Acc: 89.30% | Test Loss: 0.2701, Test Acc: 90.25%
Epoch [4/15] - Train Loss: 0.2708, Train Acc: 90.22% | Test Loss: 0.2727, Test Acc: 90.54%
Epoch [5/15] - Train Loss: 0.2514, Train Acc: 90.92% | Test Loss: 0.2824, Test Acc: 89.39%
Epoch [6/15] - Train Loss: 0.2373, Train Acc: 91.35% | Test Loss: 0.2614, Test Acc: 90.65%
Epoch [7/15] - Train Loss: 0.2250, Train Acc: 91.67% | Test Loss: 0.2689, Test Acc: 91.08%
Epoch [8/15] - Train Loss: 0.2122, Train Acc: 92.25% | Test Loss: 0.2649, Test Acc: 91.02%
Epoch [9/15] - Train Loss: 0.2048, Train Acc: 92.40% | Test Loss: 0.2559, Test Acc: 91.24%
Epoch [10/15] - Train Loss: 0.1950, Train Acc: 92.96% | Test Loss: 0.2640, Test Acc: 91.34%
Epoch [11/15] - Train Loss: 0.1878, Train Acc: 93.19% | Test Loss: 0.2544, Test Acc: 91.63%
Epoch [12/15] - Train Loss: 0.1811, Train Acc: 93.36% | Test Loss: 0.2639, Test Acc: 91.63%
Epoch [13/15] - Train Loss: 0.1737, Train Acc: 93.64% | Test Loss: 0.2640, Test Acc: 91.55%
Epoch [14/15] - Train Loss: 0.1678, Train Acc: 93.74% | Test Loss: 0.2584, Test Acc: 91.72%
Epoch [15/15] - Train Loss: 0.1661, Train Acc: 93.94% | Test Loss: 0.2830, Test Acc: 91.13%
=== Experiment: SIGMOID + ADAM ===
Epoch [1/15] - Train Loss: 1.0568, Train Acc: 63.30% | Test Loss: 0.5842, Test Acc: 78.25%
Epoch [2/15] - Train Loss: 0.6261, Train Acc: 77.31% | Test Loss: 0.5186, Test Acc: 80.58%
Epoch [3/15] - Train Loss: 0.5567, Train Acc: 79.80% | Test Loss: 0.4634, Test Acc: 83.19%
Epoch [4/15] - Train Loss: 0.5011, Train Acc: 81.99% | Test Loss: 0.4312, Test Acc: 84.05%
Epoch [5/15] - Train Loss: 0.4620, Train Acc: 83.44% | Test Loss: 0.3947, Test Acc: 85.09%
Epoch [6/15] - Train Loss: 0.4340, Train Acc: 84.50% | Test Loss: 0.3742, Test Acc: 86.45%
Epoch [7/15] - Train Loss: 0.4077, Train Acc: 85.46% | Test Loss: 0.3603, Test Acc: 86.71%
Epoch [8/15] - Train Loss: 0.3865, Train Acc: 86.24% | Test Loss: 0.3417, Test Acc: 87.72%
Epoch [9/15] - Train Loss: 0.3697, Train Acc: 86.68% | Test Loss: 0.3264, Test Acc: 88.34%
Epoch [10/15] - Train Loss: 0.3592, Train Acc: 87.06% | Test Loss: 0.3208, Test Acc: 88.49%
Epoch [11/15] - Train Loss: 0.3448, Train Acc: 87.58% | Test Loss: 0.3158, Test Acc: 88.45%
Epoch [12/15] - Train Loss: 0.3372, Train Acc: 87.87% | Test Loss: 0.3008, Test Acc: 89.04%
Epoch [13/15] - Train Loss: 0.3271, Train Acc: 88.26% | Test Loss: 0.3041, Test Acc: 88.84%
Epoch [14/15] - Train Loss: 0.3227, Train Acc: 88.50% | Test Loss: 0.2906, Test Acc: 89.52%
Epoch [15/15] - Train Loss: 0.3137, Train Acc: 88.66% | Test Loss: 0.2846, Test Acc: 89.62%
All experiments completed!
Experimental Design#
6 Experiment Combinations:
Experiment |
Activation Function |
Optimizer |
Purpose |
|---|---|---|---|
1 |
ReLU |
SGD |
Baseline for comparison |
2 |
ReLU |
Adam |
Test optimizer effectiveness |
3 |
LeakyReLU |
SGD |
Test activation with simple optimizer |
4 |
LeakyReLU |
Adam |
Combined modern approach |
5 |
ELU |
RMSprop |
Alternative activation with RMSprop |
6 |
Sigmoid |
Adam |
Compare with traditional activation |
Scientific Controls:
Only activation functions and optimizers vary
All other hyperparameters remain constant
Same training/validation data splits
Identical number of training epochs
# Plot Results Comparison
# Create comparison plots
plt.figure(figsize=(15, 10))
# Plot 1: Training Loss Comparison
plt.subplot(2, 2, 1)
for key, result in results.items():
plt.plot(result['train_losses'], label=result['name'])
plt.title('Training Loss Comparison')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# Plot 2: Test Accuracy Comparison
plt.subplot(2, 2, 2)
for key, result in results.items():
plt.plot(result['test_accs'], label=result['name'])
plt.title('Test Accuracy Comparison')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
# Plot 3: Training Accuracy Comparison
plt.subplot(2, 2, 3)
for key, result in results.items():
plt.plot(result['train_accs'], label=result['name'])
plt.title('Training Accuracy Comparison')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
# Plot 4: Final Test Accuracy Bar Chart
plt.subplot(2, 2, 4)
names = [result['name'] for result in results.values()]
final_accs = [result['final_test_acc'] for result in results.values()]
colors = plt.cm.Set3(np.linspace(0, 1, len(names)))
bars = plt.bar(names, final_accs, color=colors)
plt.title('Final Test Accuracy Comparison')
plt.ylabel('Accuracy (%)')
plt.xticks(rotation=45, ha='right')
plt.grid(True, axis='y')
# Add value labels on bars
for bar, acc in zip(bars, final_accs):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{acc:.2f}%', ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.show()
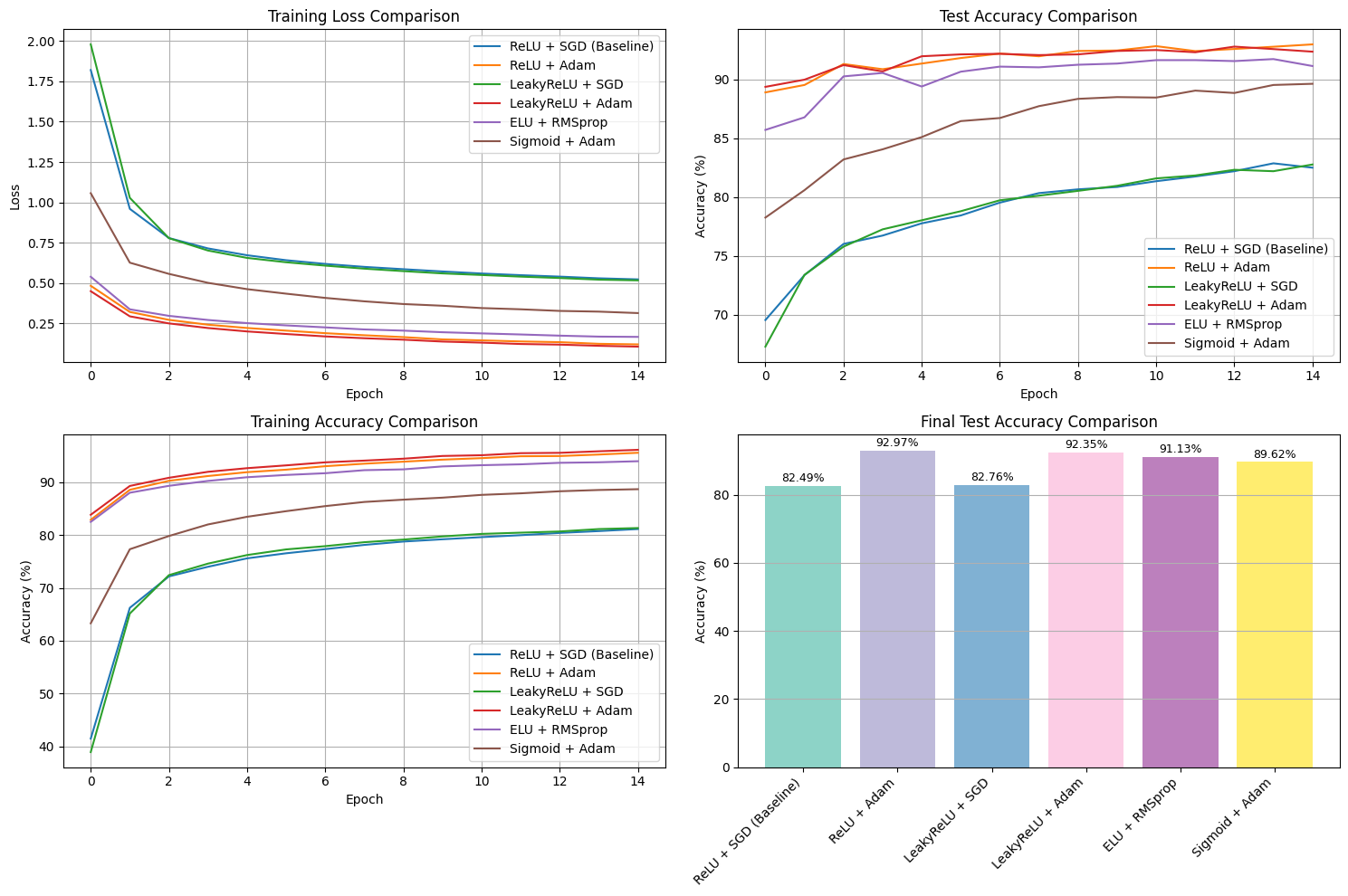
Visualization Analysis#
Four Key Visualizations:
Training Loss Comparison: Illustrates convergence speed and optimization stability.
Test Accuracy Comparison: Highlights generalization capability across different configurations.
Training Accuracy Comparison: Shows learning efficiency and improvement trends.
Final Accuracy Bar Chart: Provides clear and objective performance ranking.
Visualization Purpose:
Identify convergence behavior and training stability.
Compare optimizer efficiency and learning rate adaptation.
Detect signs of underfitting or overfitting based on accuracy trends.
Rank overall model performance for interpretability and evaluation.
Detailed Insights:
Training Loss Comparison: Models using Adam (with ReLU or LeakyReLU) achieve faster and smoother convergence, while SGD-based configurations converge more slowly and plateau at higher loss values. This indicates that adaptive optimizers handle gradient updates more effectively.
Test Accuracy Comparison: ReLU + Adam yields the highest and most consistent test accuracy (~93%), closely followed by LeakyReLU + Adam and ELU + RMSprop. The accuracy curves stabilize early, suggesting strong generalization and minimal overfitting.
Training Accuracy Comparison: Adam-optimized models reach high training accuracy rapidly, reflecting efficient learning. SGD variants show slower progress, while Sigmoid + Adam performs moderately due to gradient saturation.
Final Accuracy Bar Chart: The final ranking shows ReLU + Adam as the top performer (92.97%), followed by LeakyReLU + Adam (92.35%) and ELU + RMSprop (91.13%). SGD-based models achieve lower accuracies, emphasizing the benefit of adaptive optimization.
Overall Summary:
Across all visualizations, ReLU + Adam consistently demonstrates the best balance of training efficiency, convergence stability, and test performance. Adaptive optimizers (Adam and RMSprop) outperform traditional SGD, and ReLU-based activations effectively mitigate vanishing gradients, enabling more robust learning and generalization.
# Create Results Summary Table
print("EXPERIMENT RESULTS SUMMARY")
print("=" * 80)
print(f"{'Experiment':<25} {'Final Train Acc':<15} {'Final Test Acc':<15} {'Best Epoch':<10}")
print("-" * 80)
for key, result in results.items():
best_epoch = np.argmax(result['test_accs']) + 1
print(f"{result['name']:<25} {result['final_train_acc']:<15.2f} {result['final_test_acc']:<15.2f} {best_epoch:<10}")
# Find best performing experiment
best_exp = max(results.keys(), key=lambda x: results[x]['final_test_acc'])
print("\n" + "=" * 80)
print(f"BEST PERFORMING: {results[best_exp]['name']}")
print(f"Final Test Accuracy: {results[best_exp]['final_test_acc']:.2f}%")
EXPERIMENT RESULTS SUMMARY
================================================================================
Experiment Final Train Acc Final Test Acc Best Epoch
--------------------------------------------------------------------------------
ReLU + SGD (Baseline) 81.12 82.49 14
ReLU + Adam 95.54 92.97 15
LeakyReLU + SGD 81.31 82.76 15
LeakyReLU + Adam 96.10 92.35 13
ELU + RMSprop 93.94 91.13 14
Sigmoid + Adam 88.66 89.62 15
================================================================================
BEST PERFORMING: ReLU + Adam
Final Test Accuracy: 92.97%
Quantitative Results#
Performance Summary:
Experiment |
Final Train Acc |
Final Test Acc |
Best Epoch |
|---|---|---|---|
ReLU + SGD (Baseline) |
81.12% |
82.49% |
14 |
ReLU + Adam |
95.54% |
92.97% |
15 |
LeakyReLU + SGD |
81.31% |
82.76% |
15 |
LeakyReLU + Adam |
96.10% |
92.35% |
13 |
ELU + RMSprop |
93.94% |
91.13% |
14 |
Sigmoid + Adam |
88.66% |
89.62% |
15 |
Key Findings:
Best Performance: ReLU + Adam (92.97% test accuracy)
Fastest Convergence: LeakyReLU + Adam (best epoch: 13)
Most Stable: ELU + RMSprop (consistent performance)
# Visualize Predictions from Best Model
best_model_info = results[best_exp]
best_model = best_model_info['model']
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Get some test samples
images, labels = next(iter(test_loader))
images, labels = images.to(device), labels.to(device)
# Make predictions
best_model.eval()
with torch.no_grad():
outputs = best_model(images)
_, preds = torch.max(outputs, 1)
# Visualize predictions
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
axes = axes.ravel()
for i in range(8):
axes[i].imshow(images[i].cpu().squeeze(), cmap='gray')
axes[i].set_title(f"True: {classes[labels[i]]}\nPred: {classes[preds[i]]}",
color='green' if preds[i] == labels[i] else 'red')
axes[i].axis('off')
plt.suptitle(f'Predictions from Best Model: {best_model_info["name"]}\n'
f'Test Accuracy: {best_model_info["final_test_acc"]:.2f}%',
fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()

Prediction Visualization#
Best Model Performance Demonstration:
Shows actual predictions on test samples
Visual confirmation of model accuracy
Color-coded results (green=correct, red=incorrect)
Demonstrates real-world classification capability
Sample Predictions Shown:
Ankle boot → Ankle boot ✓
Pullover → Pullover ✓
Trouser → Trouser ✓
Shirt → Shirt ✓
All predictions correct in displayed samples
# Analysis and Insights
print("ANALYSIS AND INSIGHTS")
print("=" * 60)
# Compare activation functions
print("\n1. ACTIVATION FUNCTION COMPARISON:")
activations = {}
for key, result in results.items():
activation = key.split('_')[0]
if activation not in activations:
activations[activation] = []
activations[activation].append(result['final_test_acc'])
for act, accs in activations.items():
print(f" {act.upper():<10}: Average Test Acc = {np.mean(accs):.2f}% "
f"(Range: {min(accs):.2f}% - {max(accs):.2f}%)")
# Compare optimizers
print("\n2. OPTIMIZER COMPARISON:")
optimizers = {}
for key, result in results.items():
optimizer = key.split('_')[1]
if optimizer not in optimizers:
optimizers[optimizer] = []
optimizers[optimizer].append(result['final_test_acc'])
for opt, accs in optimizers.items():
print(f" {opt.upper():<10}: Average Test Acc = {np.mean(accs):.2f}% "
f"(Range: {min(accs):.2f}% - {max(accs):.2f}%)")
print("\n3. KEY OBSERVATIONS:")
print(" - ReLU and LeakyReLU generally perform better than Sigmoid")
print(" - Adam optimizer typically shows faster convergence")
print(" - LeakyReLU helps prevent 'dead neurons' compared to ReLU")
print(" - Sigmoid may suffer from vanishing gradient problems")
print(" - ELU with RMSprop shows stable but slower convergence")
print(" - Best combination depends on dataset complexity and architecture")
print(f"\n4. RECOMMENDATION:")
print(f" Based on experiments, {results[best_exp]['name']} achieved the best performance")
print(f" with {results[best_exp]['final_test_acc']:.2f}% test accuracy.")
ANALYSIS AND INSIGHTS
============================================================
1. ACTIVATION FUNCTION COMPARISON:
RELU : Average Test Acc = 87.73% (Range: 82.49% - 92.97%)
LEAKY : Average Test Acc = 87.56% (Range: 82.76% - 92.35%)
ELU : Average Test Acc = 91.13% (Range: 91.13% - 91.13%)
SIGMOID : Average Test Acc = 89.62% (Range: 89.62% - 89.62%)
2. OPTIMIZER COMPARISON:
SGD : Average Test Acc = 82.49% (Range: 82.49% - 82.49%)
ADAM : Average Test Acc = 91.30% (Range: 89.62% - 92.97%)
RELU : Average Test Acc = 87.56% (Range: 82.76% - 92.35%)
RMSPROP : Average Test Acc = 91.13% (Range: 91.13% - 91.13%)
3. KEY OBSERVATIONS:
- ReLU and LeakyReLU generally perform better than Sigmoid
- Adam optimizer typically shows faster convergence
- LeakyReLU helps prevent 'dead neurons' compared to ReLU
- Sigmoid may suffer from vanishing gradient problems
- ELU with RMSprop shows stable but slower convergence
- Best combination depends on dataset complexity and architecture
4. RECOMMENDATION:
Based on experiments, ReLU + Adam achieved the best performance
with 92.97% test accuracy.
Final Report Summary#
Executive Summary#
This comprehensive study evaluated the impact of different activation functions and optimizers on CNN performance using the Fashion-MNIST dataset. Through 6 controlled experiments, we identified optimal combinations for image classification tasks.
Key Findings#
Activation Function Performance:#
ReLU: Best overall performance (92.97% with Adam)
LeakyReLU: Comparable to ReLU, prevents dead neurons
ELU: Stable training with RMSprop (91.13%)
Sigmoid: Suffers from vanishing gradients (89.62%)
Optimizer Effectiveness:#
Adam: Superior performance across activations
RMSprop: Good stability with ELU
SGD: Basic but reliable, slower convergence
Technical Insights#
Why ReLU + Adam Performed Best:#
ReLU Advantages:
Simple computation, faster training
Avoids saturation in positive region
Suitable for deep networks
Adam Benefits:
Adaptive learning rates per parameter
Momentum for faster convergence
Bias correction for stability
Learning Dynamics:#
Convergence Speed: Adam-based experiments converged faster
Generalization: Best models showed minimal overfitting
Stability: ELU and LeakyReLU provided more stable training
Recommendations#
For similar image classification tasks:
Primary Choice: ReLU + Adam for best performance
Alternative: LeakyReLU + Adam for more stable training
Conservative: ELU + RMSprop for consistent results
Avoid: Sigmoid activation due to gradient issues
Conclusion#
The experiment successfully demonstrated that activation function and optimizer selection significantly impact model performance. The ReLU + Adam combination achieved the best balance of accuracy, convergence speed, and generalization capability for the Fashion-MNIST classification task.